缶は英語でも can といいますが,瓶は bin ではなく bottle といいます.bin には蓋つきの容器やごみ箱という意味があるので「物を入れる」という点では瓶と似ています.さらにこの bin には数学用語でも2つの意味があります.
■binary(2進法)
decimal(10進法)は,ある数を0から9までの整数10個を係数に使って10の冪(べき)の和で表したとき,その係数を並べて表します.例えば234は,$$\begin{align} 200+30+4&=2\times10^2+3\times10^1+4\times10^0\\&=234\end{align}$$一方, binary(2進法)は,ある数を0と1のみを係数に使って2の冪の和で表したとき,その係数を並べて表します.例えば10進法の 234 は,$$\begin{align} 234&= 128+64+32+8+2\\ &= 2^7+2^6+2^5+2^3+2^1\\&=1\times2^7+1\times2^6+1\times2^5+0\times2^4+1\times2^30\times2^2+1\times2^1+0\times2^0\\&= 11101010_{(2)}\end{align}$$となり,2進法では$11101010_{(2)}$と表されます.
因みに,ファイルの拡張子で".bin"というのがありますが,テキストファイル".txt"以外のファイル,すなわち binary file のことで,2進数で表現されています.
■frequency distribution table(度数分布表)の class(階級)
frequency distribution table の class のことを bin ともいい,ある区間ごとに分類された小グループのひとつひとつ(histogram の各棒)を意味します.data binning とは、全データをいくつかの bin に分けることをいい,data bucketing ともいいます.data を分けて容器またはバケツに入れるというイメージでしょう.したがって,histogram を作ることも data binning のひとつといえます.
# of data(データの数)を $n$ とし,それらを $x_1, x_2, ...., x_n$とします.すると,# of bins(階級の数)$k$ と bin width(階級の幅)$h$ との関係は次式で与えることができます.$$k=\frac{\max x_i-\min x_i}{h}\tag{1}$$または$$h=\frac{\max x_i-\min x_i}{k}\tag{2}$$つまり,$k$と$h$はデータの範囲を比例定数とする反比例の関係になります(値が整数にならない場合は切り上げます).
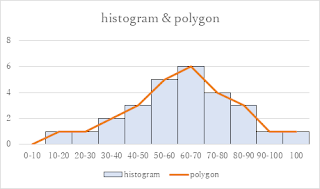
例えば,ある100点満点の試験を27名が受験した結果が次の値だったとしましょう.
76, 57, 47, 100, 47, 55, 83, 57, 49, 68, 73, 55, 68, 87, 91, 89, 37, 72, 63, 62, 57, 30, 77, 25, 60, 12, 66
$k$=10を上の式(2)に当てはめると,$$h=\frac{100-0}{10}=10$$すると$k$=10のとき$h$=10になり,frequency distribution table と graph は上図のようになります.しかし,特にこの値にしなければならないわけではありません.$$\frac{100-0}{5}=20$$なので,$k$=5のとき$h$=20,$k$=20のとき$h$=5になります.また,$$\left\lceil\frac{100-0}{7}\right\rceil=\left\lceil14.2857....\right\rceil=15$$
$\left\lceil\quad\right\rceil$は切り上げをする関数 ceiling function(天井関数)
なので,$k$=7のとき$h$=15,$k$=15のとき$h$=7になります.
この# of bins $k$とbin width $h$は data をよく眺めて直接決めてもいいのですが,実はこれらの適切な値についてはこれまでかなり研究されており,"choice","rule","formula"などと呼ばれる方法が知られています.# of data(データの数)$n$を基準にしたもの,SD=standard deviation(標準偏差)$\sigma$,IQR=interquartile range(四分位範囲)を使うものなどいろいろありますが,その中で$n$を基準にして$k$を求めるものは次の3つがあります.
① Square-root choice$$\displaystyle k=\lceil {\sqrt {n}}\rceil\displaystyle $$② Rice Rule(1944年)$$\displaystyle k=\lceil 2\sqrt[3]{n}\rceil \displaystyle$$
③ Sturges' formula(1926年)$$\displaystyle k=\lceil \log _{2}n\rceil +1$$$n$=27を代入すると,いずれも$k$=6になりますから,# of data $n$=27のときは # of bins $k$=6が適切ということになります.
 |
| ①②③のグラフ |
また,# of data $n$とSD=$\sigma$を使って$h$を求めるものに次式があります.
④ Scott’s Rule(1979年)$$\displaystyle h = \left\lceil\frac{3.49\sigma}{\sqrt[{3}]{n}}\right\rceil$$上の例の$\sigma$=20.7なので,$$\displaystyle h=\left\lceil\frac{3.49\times 20.7}{\sqrt[3]{27}}\right\rceil=\left\lceil24.08....\right\rceil=25$$となり,bin width $h$=25,# of bins $k$=4が適切ということになります.
[余談]
●Excel で frequency distribution table を作るときに frequency を求める,すなわち多数のデータの中から各 bin width(階級の幅)の度数を数える方法は,「データ分析」「FREQUENCY関数」などを使うより「COUNTIFS関数」を使う方が比較的容易にできました.例えば,ある条件範囲から0以上10以下の数を数えるには次のように入力します.
=COUNTIFS (条件範囲, ">=0", 条件範囲, "<10")
●Excel で histogram と frequency distribution polygon(度数分布多角形)を重ねて描く方法をいろいろ試してみたところ,「挿入→ヒストグラム」「データ分析→ヒストグラム」から描くよりも次の方法が比較的容易でした.
1) グラフを描く準備として,上図のような3列(一番左の列はセルの書式設定で文字列にしておく)を作る.
2) その3列を選択
3) 挿入→おすすめグラフ→すべてのグラフ→組み合わせ→集合縦棒と折れ線→OK(棒グラフと折れ線グラフができる)
4) グラフの縦棒の上で右クリック→データ系列の書式設定→要素の間隔→0%(棒グラフがヒストグラムに変わる)→色を変える
●Excel で frequency distribution table を作る前の生データから histogram だけを作るときは「挿入→ヒストグラム」が楽です.Binの幅が自動的に決まって描かれますが,横軸部分を右クリックし、メニューから「軸の書式設定」を選択して,ビンの幅,ビンのオーバーフロウ,ビンのアンダーフロウを適切に決めればOKです.
[Reference]
Histogram
Histogram – The Ultimate Guide of Binning


No comments:
Post a Comment